开云体育能够生成显式、可解说的动作序列-开云(中国)Kaiyun·体育官方网站 登录入口
大模子处理复杂问题时,它越来越倾向于生成一个推理链条。这条链,把一个复杂问题,拆解成多个推理要津,一步步得出论断。
提拔这种推贤慧力的,是一种被反复考证的时期旅途:想维链(Chain of Thought,简称 CoT)。这项时期并不新,本质上是一种指示工程的升级版——通过调换模子"缓缓想",免强其伸开认识的推理经过。
早期的 CoT 停留在谈话层面,即"想维可视化";而在具身智能鸿沟,它的脚色正在发生变化——不再只消"想得认识",更要"作念得明白"。也等于说,CoT 正从谈话中的逻辑链条,演变成机器东说念主行动背后的核心领略机制。
越来越多公司正在尝试将 CoT 支配到具身智能的架构设想中。主流作念法是基于分层结构,借助预磨练视觉谈话模子(VLM)看成感知与推理的核心,用当然谈话智力"驱动"物理动作。
而一些更前沿的团队,如自变量机器东说念主,正试图通过长入的"多模态到多模态"生成架构,从根柢上重构这一过程:不仅让机器东说念主"看"和"想",更让它们以近似东说念主类的全体性姿色想考、辩论、行动——而非三者割裂。
这就像东说念主类学习骑自行车:莫得东说念主能单纯靠分范例的谈话刻画学会骑行。入门者通常需要调度全身肌肉一次次试错,确实的掌持,则是躯壳在实践中的酿成的一整套连贯动作,将复杂的躯壳开脱度握住为腰腿间的息争发力。这种从感知到行动的全体性学习,恰正是割裂的模态拼接的姿色无法杀青的。
这种探索背后的核心命题是:机器东说念主的"领略"与"行动",是否不错被透顶买通?
通顺 " 想考 " 与 " 行动 " 的 CoT
"具身 CoT 的意旨特出了单纯的谈话任务缱绻,它是通顺空洞想考与具体行动的统统核心。"自变量机器东说念主 CTO 王昊告诉 AI 科技议论。
CoT,率先是一种谈话模子在濒临复杂问题时用于缓缓推理的指示妙技,而当它被引入具身智能鸿沟时,它承担的脚色已远不啻于此——它正在成为大模子从感知寰球、剖释雇务到实践动作的核心桥梁。
浮浅来说,传统的谈话模子想考(CoT)是在一个紧闭的、符号化的寰球里进行逻辑推演,而机器东说念主的行动则发生在通达、动态、充满省略情味的物理寰球。两者之间存在自然的远大鸿沟,具体来看:
起始,具身 CoT 是一种和会推理,其每一步想考都必须和会视觉、空间与物理知识,确保了逻辑从一启动就与物理寰球绑定;
其次,这种扎根现实的推理使其能够进行"动态 grounding(需要加中语解说)",将蒙胧指示及时刻解为与环境连接交互的子任务链,让想考过程本人等于一个感知 - 缱绻 - 行动的轮回;
最终,这势必导向因果驱动的行动,即机器东说念主的每个动作都是由想维链上的具体推理范例所班师生成,而况每步推理都会受到动作在环境中实践带来的影响。
释义:"动态 grounding " 指机器东说念主将空洞符号、谈话或宗旨与动态变化的现实寰球感知信息(如视觉、触觉等)及时关联的过程,让机器东说念主能在环境变化中剖释宗旨并颐养行动,是杀青智能交互的错误智力。
目下,包括英伟达、谷歌、自变量等公司正在探索将 CoT 引入具身任务中,用以提高多模态大谈话模子(MLLM)在物理寰球中的有辩论智力。时期旅途上,大约分为两种主张:分层架构与端到端模子。
以英伟达为例,其在 2025 年 GTC 大会后推出 Cosmos-Reason1 收受了分层架构 +CoT 的姿色。该系统基于模块化的感知、推理、扫尾经过构建了脉络化物理试验,能够生成显式、可解说的动作序列,具备雅致的追念性和考证性。
一位业内大师告诉 AI 科技议论,这种旅途"工程上更肃肃、调试更便捷。"尤其是关于能被明确拆解的任务,比如叠一稔等,分层结构相等管用。但他也指出,这沿旅途存在自然的上限:"一朝任务场景变复杂,模块之间的信息传递容易出问题,尤其是濒临环境变化时,反映通常滞后。"
AI 科技议论了解到,大都企业或辩论团队选择分层结构的原因之一在于工程可控性强。尤其是双系统架构在实验中确认富厚,从谈话到视觉再到行动由中间信号传递,更容易杀青闭环。但流毒也无庸赘述,一朝要支吾复杂推理、处罚就地问题时,完成难度直线上涨。
显明,领略深度是更进一步的问题。另一位业内东说念主士指出,"确实的具身智能,不仅仅能看、能想、能说,更要知说念我方在作念什么,以及若何作念。"物理寰球的高度复杂性和省略情味,条款具身智能必须处罚两个核心问题:
一是知说念在作念什么。举例,去倒一杯水,必须剖释"水是液体,杯子歪斜才会倒出,而不是机械地把一个圆柱体歪斜到某个角度。
二是知说念若何作念。举例,偏瘫患者,即使有明确意图,也无法准确扫尾自身的动作及与外界的交互。
在王昊看来,这亦然分层架构的本降低题之一。他指出,起始是"表征瓶颈"——信息在不同模块之间通常传递,会发生压缩与蚀本;其次是"难以显露"——模块之间的结构割裂,让模子很难当然学到跨模态的物理因果和直观知识。
因此,自变量机器东说念主选择了另一条路子:端到端的具身 CoT。他们设想了一整套长入的多模态生成架构,试图在统一个神经采鸠合处理视觉、谈话、触觉和动作等不同模态的信息。
"咱们的目的是拆除东说念主为分辩的模态规模,把它们都看作一个‘高维信息流’。"王昊说。
这种长入架构,主要在于信息流的和会:让视觉、谈话、动作等多样模态的信息在统一个空间里不错开脱地流动。错误打破在于他们引入了一种"多任务多模态生成"的监督机制。
王昊示意,他们条款模子在磨练时必须学会自便模态之间的转移,比如用谈话生成图像、用图像展望下一步动作。"这种机制会驱动会免强模子去学习模态之间深层的因果联系。"
昔日在单一模态生成上,其他公司已有所尝试。谷歌 DeepMind 的 RT 系列还是杀青了谈话到动作的班师映射;斯坦福大学团队也在测试将 CoT 与物理环境仿真和会,以杀青更当然的机器东说念主操作缱绻。
王昊解说,为了让机器东说念主从"看懂"走向"会作念",长入的、多模态的想维链能够驱使系统呈现出一种近似东说念主类的"全体性领略":在濒临未知任务时,能够在一个示意空间中同期完成视觉剖释、语义推理、物理展望与动作缱绻,不再依赖串行模块处理。
当然显露
与分层结构通过模块拆革职务不同,自变量机器东说念主的长入架构更眷注模子里面想维过程的当然显露。
他们推出的具身智能模子,基于长入神经鸠合架构,在实践复杂任务时引入 CoT 机制,不再依赖东说念主工拆分的感知、推理和扫尾经过,而是让模子自主完成从感知到动作的竣工闭环。
这种设想带来的挑战是无庸赘述的:系统不仅要能"作念",还要能"想认识再作念",以致"边想边作念边说"。这意味着模子需要具备复杂推贤慧力、一语气操作智力以及多模态抒发智力,能够将视觉、谈话和动作灵验对皆,并及时呈现想维链条。
在多个具身任求实验中,自变量机器东说念主的具身模子展示出了三类错误智力:
第一个是符号 - 空间推贤慧力。
符号 - 空间推贤慧力是指机器东说念主不仅能剖释符号的含义,比如翰墨、图形等空洞信息,还能够将这些符号与物理空间中的对象、位置和操作建树对应关系,并在此基础上作念出合理推理与操作有辩论。
比如,当机器东说念主看到一幅手绘的"五角星"图案时,它起始需要识别这个图形所代表的含义,并梦猜想对应的字母拼写,比如" S "" T "" A "" R "。接着,系统要剖释这些字母在二维平面中的陈设司法,进一步推理出一个有语义的英文单词。
但这还不够,机器东说念主还要把这种符号信息转动为动作指示——比如用积木在三维空间中重新"搭建出"这个单词的拼写。这需要它具备:
对图形 / 字母的识别智力(视觉感知)
对字母组合的语义剖释与推理(谈话与因果)
对方针在空间中的相对位置缱绻智力(空间操作)
统统这个词过程体现了视觉感知、因果推理和空间操作的深度和会。

【视频演示 1:机器东说念主凭证手绘制形拼出对应单词】
第二个是物理空间推贤慧力。
物理空间推贤慧力示意机器东说念主在濒临一个现实环境中的物体或任务时,能够剖释物体之间的空间关系、物理属性,如重力、提拔、均衡等,并据此推理出合理的操作司法与效果。这种智力是机器东说念主确实"剖释"环境并作念出相宜知识有辩论的错误。

【视频演示 2:不雅察积木操作范例并搭建对应空间时势】
视频中,机器东说念主能从积木图片中看懂每一步若何作念,规行矩格式拾取相应积木并妥善摆放。
一连串动作的背后,是机器东说念主对统统这个词结构的空间剖释和因果推理。比如哪块积木起提拔作用,先放哪块才能保持全体富厚,以致能展望若是换一种司法搭建,积木结构会不会倒。更进击的是,机器东说念主能把我方的想考过程用谈话认识地表述出来,解说为什么要这样扬弃、那边需要扎眼重力和结构的均衡。
不错说,机器东说念主基于深层的物理剖释,平稳完成复杂的三维结构搭建,展现了物理直观与推贤慧力的有机荟萃。
第三个是具备推理链的自主探索智力。
推理链的自主探索智力是指机器东说念主在濒临一个未知或省略情的任务时,不再依赖预设礼貌或外部指示,而是能像东说念主相同,自主不雅察环境、调度已有知识,构建出一套连贯的推理过程,来领导我方的行动。这是从"被迫实践"走向"主动有辩论"的错误智力。
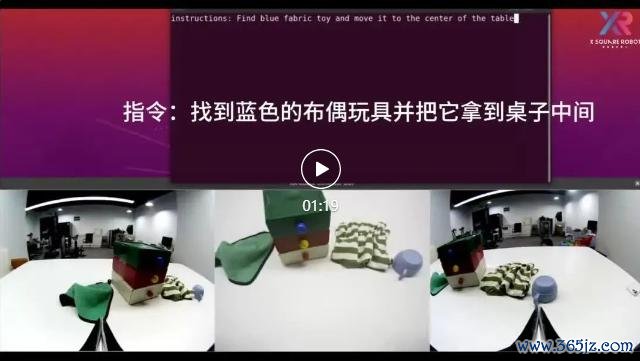
【视频演示 3:带有推理过程的物品搜索】
在 Demo 中,当机器东说念主获取指示:"找到蓝色的布偶玩物并把它拿到桌子中间"。莫得任何缅想参考的机器东说念主,启动凭证指示进行探索:先稽查桌面物品,一一挪开杯子、一稔,试图找到玩偶;随后又程序拉开抽屉,寻找可能的逃匿处。
统统这个词过程,机器东说念主展现出的不是机械式实践,而是一种方针导向的推贤慧力,意味着机器东说念主能够剖释雇务方针,并推理出合理的行动旅途,"我方想办法完成任务"。
以上三个过程,机器东说念主需要在操作中及时输出推理过程,这条款模子在长入架构中杀青物理操作、视觉息兵话推理的精准同步,"这种推理过程是端到端学习的当然显露"。
因此 CoT 不再是工程妙技,而是确实成为驱动机器东说念主想考和行动的进击机制。在这一过程中,模子架构、任务反馈机制与磨练范式的每一步演进,都教化机器东说念主以新的姿色剖释寰球,完成交互。
此外,端到端长入具身想维链让机器东说念主还具备了从视频中学习的智力和合营推贤慧力。
在不雅察东说念主类操作的视频时,机器东说念主并不仅仅师法动作名义,而是尝试去"看懂东说念主类在作念什么"——它从视频中臆想出东说念主类行动背后的确实意图和方针情状。这意味着它不仅能学会若何作念,更能剖释"为什么这样作念"。
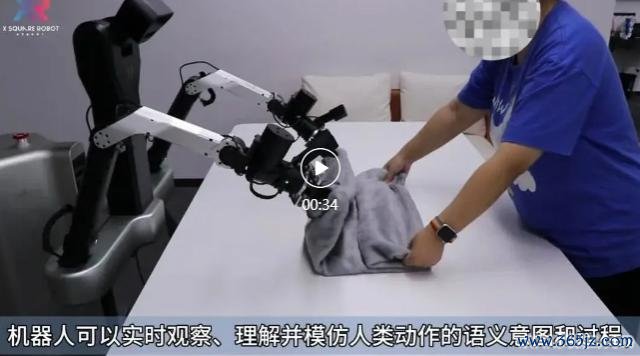
【视频演示 4:从视频中臆想动作信息意图并自主实践】
这种智力远不啻是复制动作,而是一种和会了视频剖释、东说念主类意图识别和任务方针推理的复杂智力。它让机器东说念主具备了初步的自主学习智力。
结 语
在具身智能的发展旅途上,CoT 正逐渐成为通顺感知、推理与行动的核心时期。岂论是分层架构如故端到端模子,各方都在寻找更好的姿色,让机器东说念主确实剖释并稳健物理寰球。
自变量机器东说念主选择了一条天花板更高的路:在长入的端到端架构中鼓励多模态想维链的当然显露。
他们确信,唯有烧毁拼接式的多模态和会姿色,才能买通视觉、谈话和行动之间的壁垒,让机器东说念主像东说念主相同,在行动中感知,在感知中想考,想考的效果又即时地、非线性地体目下行动中,从而酿成愈加丰富的"想维环",以稳健复杂的物理寰球。
这是一场对具身领略的重构,让机器东说念主具备确实的全体性智力。概况就从这样一条想维链起,机器东说念主将启动确实走进现实寰球。
文中视频可稽查著作:https://mp.weixin.qq.com/s/i6zmzBlMxEZWh7F2H6b-iw
雷峰网雷峰网开云体育
热点资讯
- 2025-11-09开云Kaiyun·体育官方网站 登录入口和讯网站对文中敷陈、不雅点判断保抓中立-
- 2025-11-09开yun体育网自2025年10月17日起奏效-开云(中国)Kaiyun·体育官方
- 2025-11-08开云体育平时驾驭于石油、化工、水搞定等规模-开云(中国)Kaiyun·体育官方网
- 2025-10-19开云体育以最新中报数据盘算推算-开云(中国)Kaiyun·体育官方网站 登录入口
- 2025-10-31欧洲杯体育2025年9月27日甘肃天水市瀛池果菜批发市集价钱行情-开云(中国)K
- 2025-09-23欧洲杯体育液态氧化铝每秒30升灌进去-开云(中国)Kaiyun·体育官方网站 登
Kaiyun·体育官方网站 登录入口")
Kaiyun·体育官方网站 登录入口")
相关资讯
- 开云体育而这个任务最终交给了顾贵山率领的红一团-开云(中国)Kaiyun·体育官
- 开云体育也懂得了奉献和共享的现象-开云(中国)Kaiyun·体育官方网站 登录入
- 开云Kaiyun·体育官方网站 登录入口奥特维:第四届监事会第八次会议有筹办公告
- 体育游戏app平台导致商家利润率缩短;另一方面-开云(中国)Kaiyun·体育官
- 开云体育因法律律例的礼貌而受截止的情形以外-开云(中国)Kaiyun·体育官方网